Task 05 网络设计的技巧
5 Task05:观看 2021版视频 视频 P5-9:网络设计的技巧(2天)开源文档:https://datawhalechina.github.io/leeml-notes ;视频地址:https://www.bilibili.com/video/BV11K4y1S7AD?p=5
Task 05 网络设计的技巧
1. When gradient is small …
1.1 优化(Optimization)损失函数失败的原因
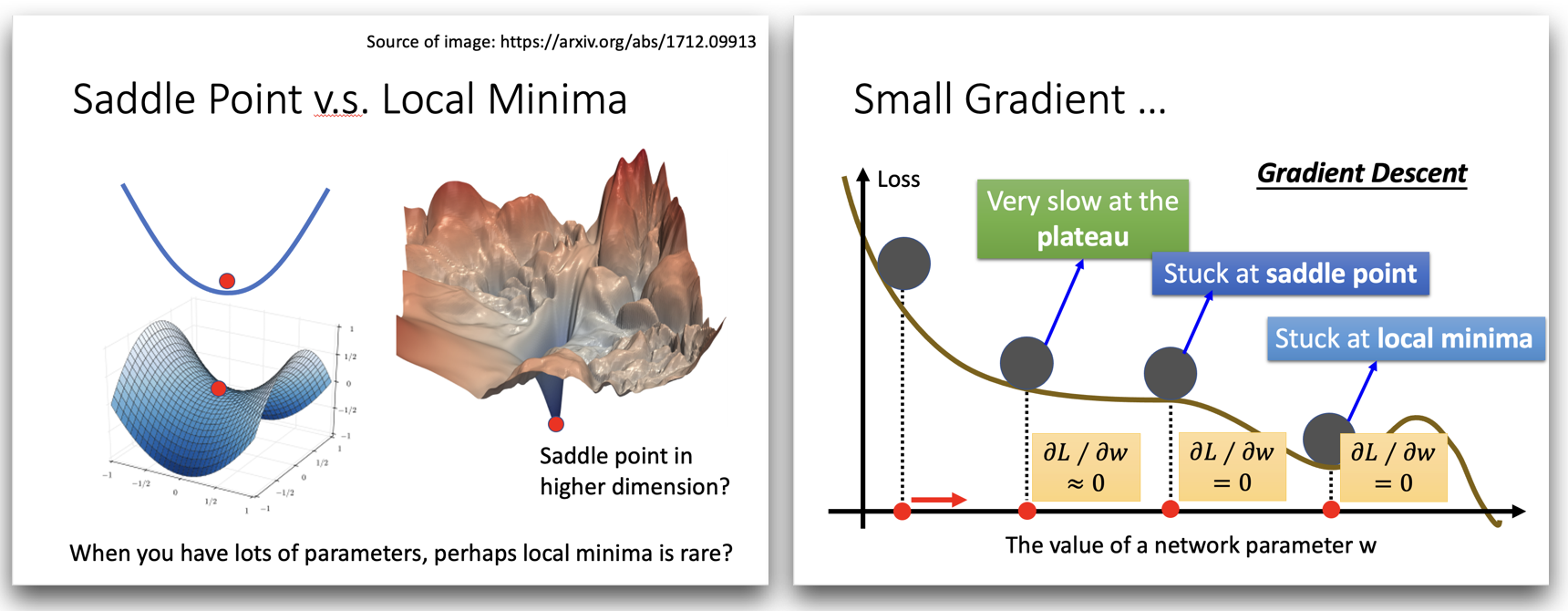
梯度下降 优化(Optimization) 失败的原因(梯度值接近于0,是一个临界点) (gradient is close to zero, critical point)
- 局部最小值 (local minima)
- 鞍点 (saddle point)


经常看似局部最小值的点(More “like” local minima),在高维空间其实并不是一个局部最小值点(never reach a real “local minima”)。
1.2 优化(Optimization)失败的时候,如何把梯度下降做的更好?(Tips for training: Batch and Momentum)
1.2.1 Batch
Shuffle:每个epoch之前进行重新分batch,每个epoch的batch内容都是不一样的。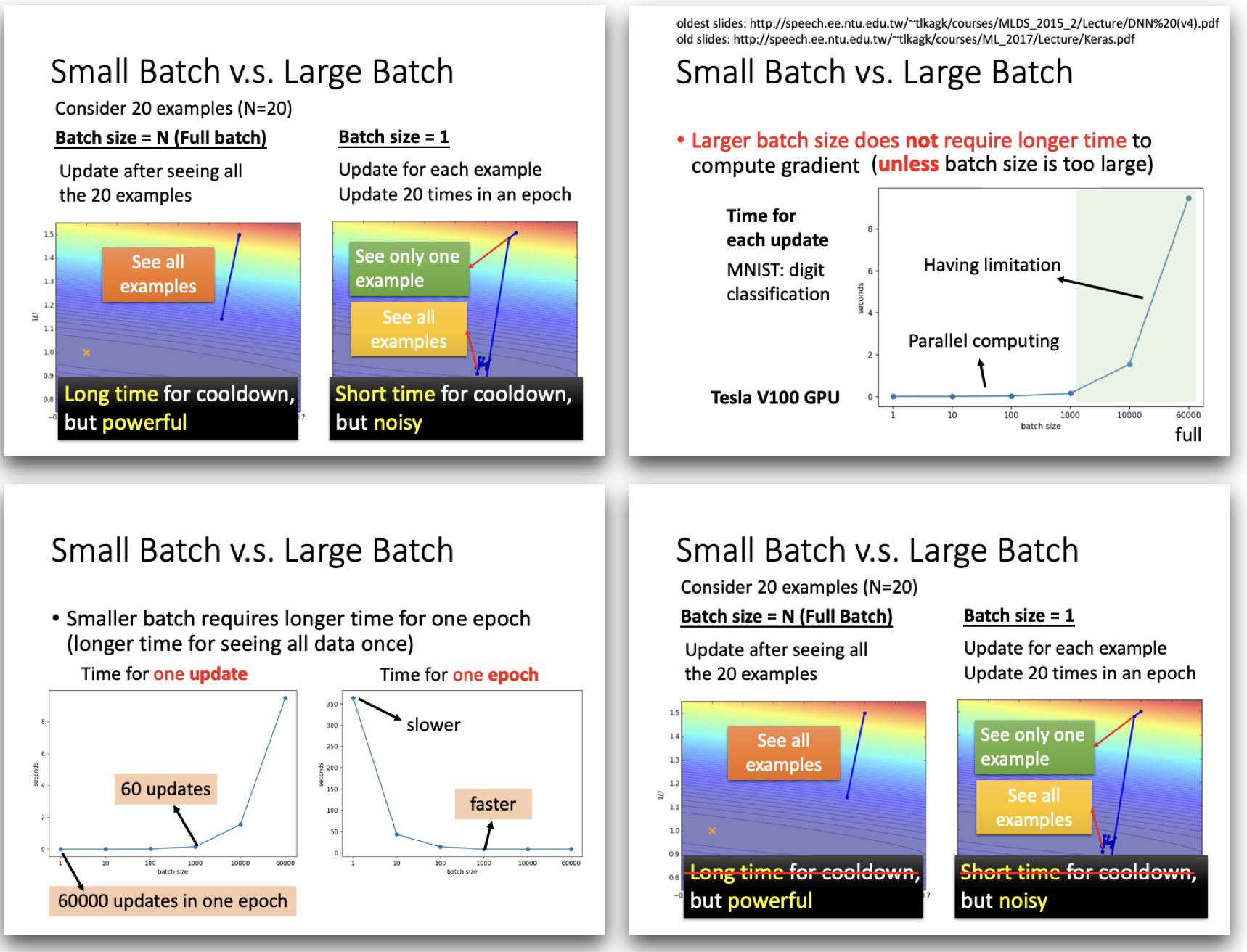

1.2.2 Momentum

Concluding Remarks
- Critical points have zero gradients.
Critical points can be either saddle points or local minima.
- Can be determined by the Hessian matrix.
- It is possible to escape saddle points along the direction of eigenvectors of the Hessian matrix.
- Local minima may be rare.
- Smaller batch size and momentum help escape critical points.
1.2.3 给每一个参数不同的学习率lr(Aptive Learning Rate)
零界点(critical point)不一定是你在训练network时遇到的最大的困难。
很多时候我们都没有确认loss不变的时候,梯度值是不是就是0。有时候loss不变的时候,梯度值可能并不是0,也不是local minima,也不是saddle points。


最常用的Optimization策略,Adam

Learning Rate Scheduling

1.3 Summary of Optimization

2. 分类
详细版教程:
2.1 分类与回归的关系和区别 (Classification vs Regression)

2.2 Softmax

3. Batch Normalization
Make different features have the same scaling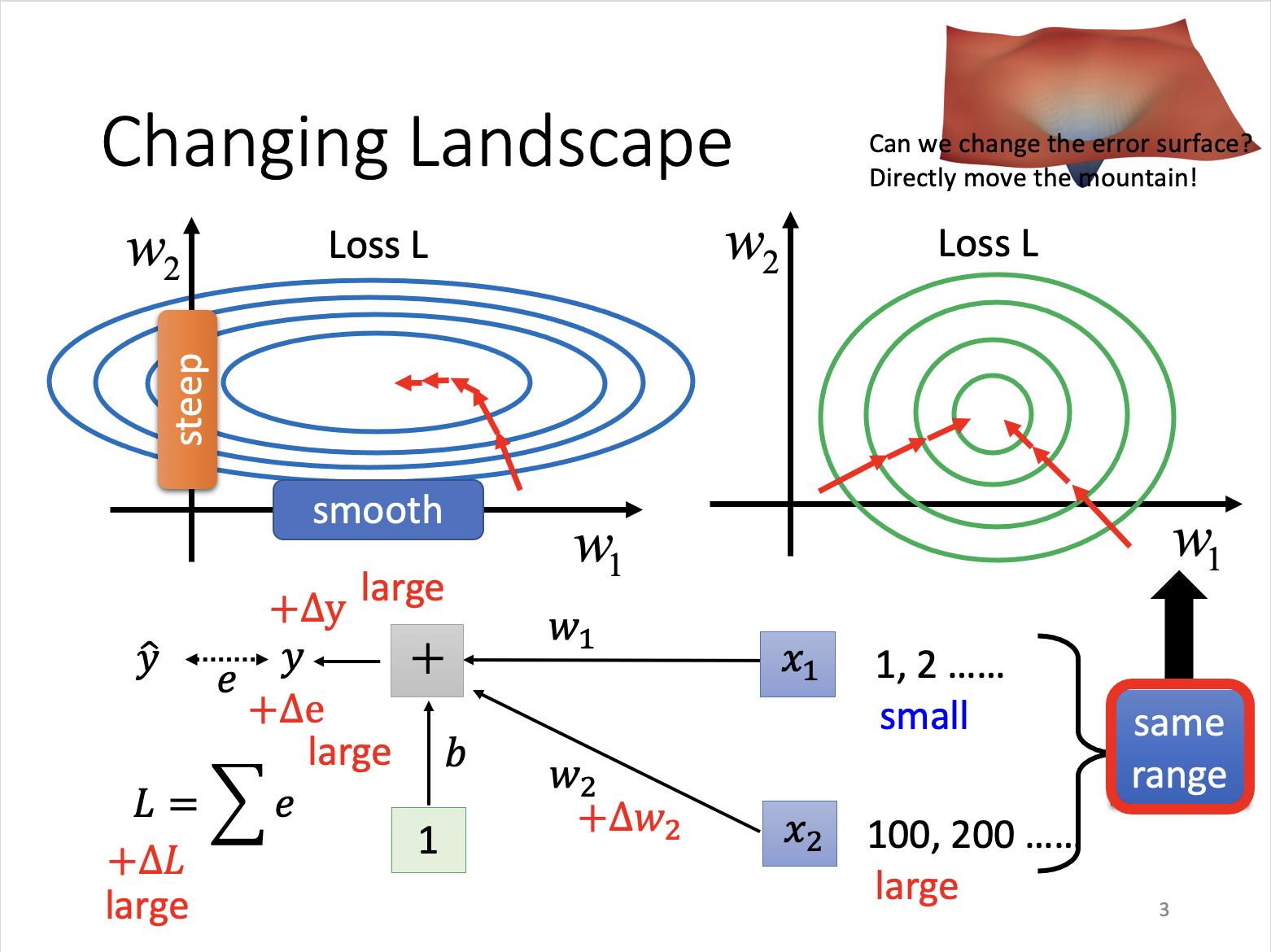
3.1 Feature Normalization

3.2 Batch Normalization

- Batch 不可以太小!!!!!

- 一般不使用Sigmoid,因为很难训练,一般使用ReLU。
Reference:
本作品采用 知识共享署名-相同方式共享 4.0 国际许可协议 进行许可。
评论已关闭